Play for Scala-Deconstructing Play
更新日期:
- 1. Drawing the architectural big picture
- 2. Application configuration
- 3. The model—adding data structures and business logic
- 3.1. Database-centric design
- 3.2. Model class design
- 3.3. Defining case classes
- 3.4. Persistence API integration
- 3.5. Using Slick for database access
- 4. Controllers—handling HTTP requests and responses
- 4.1. URL-centric design
- 4.2. Routing HTTP requests to controller action methods
- 4.3. Binding HTTP data to Scala objects
- 4.4. Generating different types of HTTP response
- 5. View template—formatting output
- 5.1. UI-centric design
- 5.2. HTML-first templates
- 5.3. Type-safe Scala templates
- 5.4. Rendering templates—Scala template functions
- 6. Static and compiled assets
- 7. Jobs—starting processes
- 8. Modules—structuring your application
Drawing the architectural big picture
When a web client sends HTTP requests to a Play application, the request is handled by the embedded HTTP server, which provides the Play framework’s network interface. The server forwards the request data to the Play framework, which generates a response that the server sends to the client.
The Play server
Play’s HTTP server is JBoss Netty, one of several Java NIO non-blocking servers.
When you use a web framework that’s based on the Java Servlet API, you package your web application as some kind of archive that you deploy to an application server such as Tomcat, which runs your application.
With the Play framework it’s different: Play includes its own embedded HTTP server, so you don’t need a separate application server to run your application.
MVC
The MVC design pattern separates an application’s logic and data from the user interface’s presentation and interaction, maintaining a loose coupling between the separate components.
The Play framework achieves all of this with fewer layers than traditional Java EE web frameworks by using the controller API to expose the HTTP directly, using HTTP concepts, instead of trying to provide an abstraction on top of it.
REST
REST is an architectural style that characterizes the way HTTP works, featuring constraints such as stateless client-server interaction and a uniform interface.
Application configuration
Play creates an initial configuration file for you, and almost all of the many configuration parameters are optional, with sensible defaults, so you don’t need to set them all yourself.
Creating the default configuration
conf/application.conf
1 2 3 4 5 6 | application.secret="l:2e>xI9kj@GkHu?K9D[L5OU=Dc<8i6jugIVE^[`?xSF]udB8ke" application.langs="en" logger.root=ERROR logger.play=INFO logger.application=DEBUG |
Configuration file format
Play uses the Typesafe config library (https://github.com/typesafehub/config).
1 2 3 4 5 6 7 | logger.net.sf.ehcache.Cache=DEBUG logger.net.sf.ehcache.CacheManager=${logger.net.sf.ehcache.Cache} logger.net.sf.ehcache.store.MemoryStore=${logger.net.sf.ehcache.Cache} log.directory = /var/log log.access = ${log.directory}/access.log log.errors = ${log.directory}/errors.log |
include
1 2 3 4 5 6 7 8 | db: { default: { driver: "org.h2.Driver", url: "jdbc:h2:mem:play", user: "sa", password: "", } } |
application.conf
1 2 3 4 | include "db-default.conf" # override user name and password db.default.user = products db.default.password = clippy |
MERGING VALUES FROM MULTIPLE FILES
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | db: { default: { user: "products" password: "clippy must die!" logStatements: true } } // 方式二, 加逗号 db: { default: { user: "products", password: "clippy must die!", logStatements: true, } } // 方式三 db.default.driver = org.h2.Driver db.default.url = jdbc:h2:mem:play db.default.user = products db.default.password = "clippy must die!" db.default.logStatements = true |
The configuration format is specified in detail by the Human-Optimized Config Object Notation (HOCON ) specification (https://github.com/typesafehub/config/blob/master/HOCON.md).
Configuration file overrides
1 2 3 4 | start -Ddb.default.url=postgres://localhost:products@clippy/products run -Dconfig.file=conf/production.conf run -Dconfig.file=/etc/products/production.conf |
Custom application configuration
For example, suppose you want to display version information in your web applica-
tion’s page footer.
application.conf
1 | application.revision = 42 |
1 2 3 4 | @import play.api.Play.current <footer> Revision @current.configuration.getString("application.revision") </footer> |
The getString method returns an Option[String] rather than a String, but the template outputs the value or an empty string, depending on whether the Option has a value.
The model—adding data structures and business logic
The model contains the application’s domain-specific data and logic.
This data is usually kept in persistent storage, such as a relational database, in which case the model handles persistence.
In a layered application architecture, the domain-specific logic is usually called business logic and doesn’t have a dependency on any of the application’s external inter- faces, such as a web-based user interface.
Database-centric design
One good way to design an application is to start with a logical data model, as well as an actual physical database.
Database-centric design means starting with the data model: identifying entities and their attributes and relationships.
For example, we can design a product catalog application by first designing a data- base for all of the data that we’ll process.
- Product—A Product is a description of a manufactured product as it might appear in a catalog, such as “Box of 1000 large plain paperclips,” but not an actual box of paperclips. Attributes include a product code, name, and description.
- Stock Item—A Stock Item is a certain quantity of some product at some location, such as 500 boxes of a certain kind of paperclip, in a particular Warehouse. Attributes include quantity and references to a Product and Warehouse.
- Warehouse—A Warehouse is a place where Stock Items are stored. Attributes include a name and geographic location or address.
- Order—An Order is a request to transfer ownership of some quantity of one or more Products, specified by Order Lines. Attributes include a date, seller, and buyer.
- Order Line—An Order Line specifies a certain quantity of some Product, as part of an Order. Attributes include a quantity and a reference to an Order and Product.
The benefit of this approach is that you can use established data modeling techniques to come up with a data model that consistently and unambiguously describes your application’s domain.
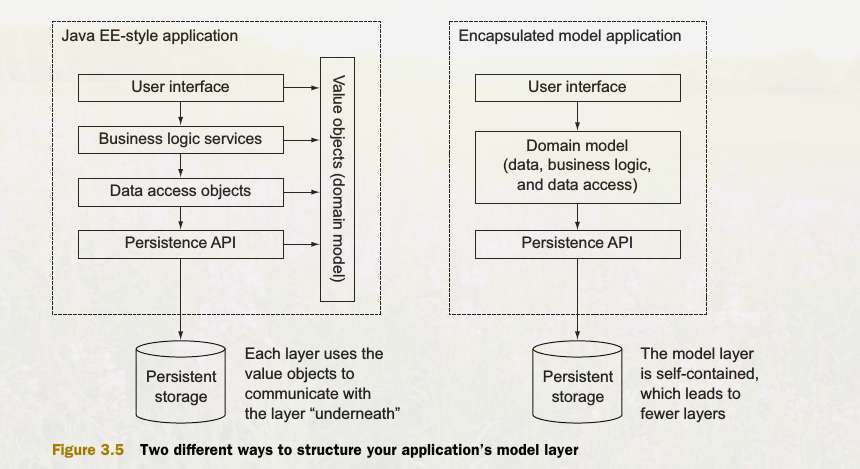
Model class design
There’s more than one way to structure your model. Perhaps the most significant choice is whether to keep your domain-specific data and logic separate or together.
Developers coming to Play and Scala from a Java EE background are likely to have separated data and behavior in the past, whereas other developers may have used a more object-oriented approach that mixes data and behavior in model classes.
More generally, the domain data model is specified by classes called value objects that don’t contain any logic.
Defining case classes
We need case classes to represent quantities of various products stored in warehouses.
1 2 3 4 5 6 7 8 9 10 11 12 13 | case class Product( id: Long, ean: Long, name: String, description: String) case class Warehouse(id: Long, name: String) case class StockItem( id: Long, productId: Long, warehouseId: Long, quantity: Long) |
Persistence API integration
You can use your case classes to persist the model using a persistence API. In a Play application’s architecture, this is entirely separate from the web tier; only the model uses (has a dependency on) the persistence API, which in turn uses external persistent storage, such as a relational database.
Play includes the Anorm persistence API so that you can build a complete web application, including SQL database access, without any additional libraries. But you’re free to use alternative persistence libraries or approaches to persistent storage, such as the newer Slick library.
Using Slick for database access
Slick is intended as a Scala-based API for relational-database access.
The idea behind Slick is that you use it instead of using JDBC directly or adding a complex object-relational mapping framework. Instead, Slick uses Scala language featuresb to allow you to map database tables to Scala collections and to execute queries.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | object Product extends Table[(Long, String, String)]("products") { def ean = column[Long]("ean", O.PrimaryKey) def name = column[String]("name") def description = column[String]("description") def * = ean ~ name ~ description } // you define a query on the Product object: val products = for { product <- Product.sortBy(product => product.name.asc) } yield (product) // To execute the query, you can use the query object to generate a list of products, // in a database session: val url = "jdbc:postgresql://localhost/slick?user=slick&password=slick" Database.forURL(url, driver = "org.postgresql.Driver") withSession { val productList = products.list } |
Controllers—handling HTTP requests and responses
One aspect of designing your application is to design a URL scheme for HTTP requests, hyperlinks, HTML forms, and possibly a public API. In Play, you define this interface in an HTTP routes configuration and implement the interface in Scala controller classes.
More specifically, controllers are the Scala classes that define your application’s HTTP interface, and your routes configuration determines which controller method a given HTTP request will invoke.
These controller methods are called actions—Play’s architecture is in fact an MVC variant called action-based MVC—so you can also think of a controller class as a collection of action methods.
URL-centric design
This URL-centric design is an alternative to a database-centric design that starts with the application’s data, or a UI-centric design that’s based on how users will interact with its user interface.
URL-centric design isn’t better than data model–centric design or UI-centric design, although it might make more sense for a developer who thinks in a certain way, or for a certain kind of application.
Http resources
URL-centric design means identifying your application’s resources, and operations on those resources, and creating a series of URLs that provide HTTP access to those resources and operations.
Once you have a solid design, you can add a user-interface layer on top of this HTTP interface, and add a model that backs the HTTP resources.
The key benefit of this approach is that you can create a consistent public API for your application that’s more stable than either the physical data model represented by its model classes, or the user interface generated by its view templates.
RESTful web services
This kind of API is often called a RESTful web service, which means that the API is a web service API that conforms to the architectural constraints of representational state transfer (REST).
RESOURCE-ORIENTED ARCHITECTURE
Modeling HTTP resources is especially useful if the HTTP API is the basis for more than one external interface, in what can be called a resource-oriented architecture—a REST -style alternative to service-oriented architecture based on addressable resources.
Resource-oriented architecture is an API-centric perspective on your application, in which you consider that HTTP requests won’t necessarily come from your own application’s web-based user interface.
Routing HTTP requests to controller action methods
For example, a URL -centric design for our product catalog might give us a URL scheme with the following URLs:
1 2 3 4 5 6 7 8 9 10 11 | GET / GET /products GET /products?page=2 GET /products?filter=zinc GET /product/5010255079763 GET /product/5010255079763/edit PUT /product/5010255079763 |
You create a conf/routes file like this
1 2 3 4 5 | GET / controllers.Application.home() GET /products controllers.Products.list(page: Int ?= 1) GET /product/:ean controllers.Products.details(ean: Long) GET /product/:ean/edit controllers.Products.edit(ean: Long) PUT /product/$ean<\d{13}> controllers.Products.update(ean: Long) |
Binding HTTP data to Scala objects
Action methods often have parameters, and you also need to be able to map HTTP request data to those parameters.
Generating different types of HTTP response
An HTTP response is not only a response body; the response also includes HTTP status codes and HTTP headers that provide additional information about the response.
View template—formatting output
A web framework’s approach to formatting output is a critical design choice. View templates are a big deal; HTML templates in particular.
UI-centric design
URL-centric design that focuses on the application’s HTTP API.
UI-centric design starts with user-interface mockups and progressively adds detail without starting on the underlying implementation until later, when the interface design is established. This approach has become especially popular with the rise of SAAS (software as a service) applications.
SAAS APPLICATIONS
37signals popularized UI-centric design in their book Getting Real (http://gettingreal.37signals.com/ch09_Interface_First.php), which describes the approach as “interface first,” meaning simply that you should “design the interface before you start programming.”
UI-centric design works well for software that focuses on simplicity and usability, because functionality must literally compete for space in the UI, whereas functionality that you can’t see doesn’t exist.
In this scenario, database-centric design may seem less relevant because the database design gets less attention than the UI design, for early versions of the software, at least.
MOBILE APPLICATIONS
UI-centric design is also a good idea for mobile applications, because it’s better to address mobile devices’ design constraints from the start than to attempt to squeeze a desktop UI into a small screen later in the development process.
HTML-first templates
There are two kinds of web framework templating systems, each addressing different developer goals: component systems and raw HTML templates.
USER-INTERFACE COMPONENTS
One approach minimizes the amount of HTML you write, usually by providing a user-interface component library.
The idea is that you construct your user interface from UI “building blocks” instead of writing HTML by hand.
In principle, the benefit of this approach is that it results in a more consistent UI with less coding, and there are various frameworks that achieve this goal. But the risk is that the UI components are a leaky abstraction, and that you’ll end up having to debug invalid or otherwise non-working HTML and JavaScript after all.
HTML TEMPLATES
A different kind of template system works by decorating HTML to make content dynamic, usually with syntax that provides a combination of tags for things like control structures and iteration, and an expression language for outputting dynamic values.
The benefits of starting with HTML become apparent in practice, due to a combina- tion of factors.
JAVASCRIPT WIDGETS
The opportunity to use a wide selection of JavaScript widgets is the most apparent practical result of having control over your application’s HTML.
JavaScript widgets are different from framework-specific widgets, because they can work with any server-side code that gives you control over your HTML and the HTTP interface.
Being in control of the HTML your templates produce means that you have a rich choice of JavaScript widgets.
Type-safe Scala templates
Play includes a template engine that’s designed to output any kind of text-based format, the usual examples being HTML, XML, and plain text.
STARTING WITH A MINIMAL TEMPLATE
To start with, minimum interference means that all of the template syntax is optional.
app/views/minimal.scala.html
1 2 3 4 5 6 | <!DOCTYPE html> <html> <head> <title></title> </head> </html> |
ADDING DYNAMIC CONTENT
app/views/title.scala.html
1 2 3 4 5 6 7 | @(title:String) <!DOCTYPE html> <html> <head> <title>@title</title> </head> </html> |
BASIC TEMPLATE SYNTAX
The parameter declaration, like all template syntax,
starts with the special @ character,
which is followed by a normal Scala function parameter list.
In the body of a template, the @ character can be followed by any Scala
expression or statement, whose value is inserted into the rendered template output.
Rendering templates—Scala template functions
To use the template in the previous example, we first need to save it in a file in the
application, such as app/views/products.scala.html. Then we can render the
template in a controller by calling the template function:
val html = views.html.title("New Arrivals")
This results in the following compiled template—a file in
target/scala-2.10/src_managed/main/views/html/
Static and compiled assets
A typical web application includes static content—images, JavaScript, stylesheets, and downloads. In Play, these files are called assets.
Serving assets
Play provides an assets controller whose purpose is to serve static files. There are two advantages to this approach: you use the usual routes configuration and you get additional functionality in the assets controller.
Using the routes configuration for assets means that you have the same flexibility in mapping URLs as you do for dynamic content.
On top of routing, the assets controller provides additional functionality that’s useful for improving performance when serving static files:
- Caching support—Generating HTTP Entity Tags (ETags) to enable caching
- JavaScript minification—Using Google Closure Compiler to reduce the size of JavaScript files
Compiling assets
Play supports one of each: LESS and CoffeeScript, languages that improve on CSS and JavaScript, respectively.
At compile time, LESS and CoffeeScript assets are compiled into CSS and JavaScript files. HTTP requests for these assets are handled by the assets controller.
Jobs—starting processes
Sometimes an application has to run some code outside the normal HTTP request- response cycle, either because it’s a long-running task that the web client doesn’t have to wait for, or because the task must be executed on a regular cycle, independently of any user or client interaction. Today, architectures are frequently web-centric, based around a web application or deployed on a cloud-based application hosting service. These architectures mean that we need a way to schedule and execute these jobs from within our web application.
Asynchronous jobs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | import java.util.Date import models.PickList import scala.concurrent.{ExecutionContext, future} def sendAsync(warehouse: String) = Action { import ExecutionContext.Implicits.global future { // Use Scala future to execute block of code asynchronously val pickList = PickList.find(warehouse) send(views.html.pickList(warehouse, pickList, new Date)) } // Build, render, and send pick list somewhere Redirect(routes.PickLists.index()) } |
This time, the template rendering code is wrapped in a call
to scala.concurrent.future, which executes the code asynchronously.
Scheduled jobs
Depending on how our warehouse works, it may be more useful to automatically generate a new pick list every half hour.
To do this, we need a scheduled job that’s triggered automatically, without needing anyone to click the button in the user interface. Play doesn’t provide scheduling functionality directly, but instead integrates with Akka, a library for actor-based concurrency that’s included with Play.
app/Global.scala
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | import akka.actor.{Actor, Props} import models.Warehouse import play.api.libs.concurrent.Akka import play.api.GlobalSettings import play.api.templates.Html import play.api.libs.concurrent.Execution.Implicits.defaultContext object Global extends GlobalSettings { override def onStart(application: play.api.Application) { import scala.concurrent.duration._ import play.api.Play.current // Run when Play application starts for (warehouse <- Warehouse.find()) { val actor = Akka.system.actorOf( Props(new PickListActor(warehouse)) ) // Create actor for each warehouse Akka.system.scheduler.schedule( 0.seconds, 30.minutes, actor, "send" ) } } } |
Asynchronous results and suspended requests
app/controllers/Dashboard.scala
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | package controllers import play.api.mvc.{Action, Controller} import concurrent.{ExecutionContext, Future} object Dashboard extends Controller { def backlog(warehouse: String) = Action { import ExecutionContext.Implicits.global val backlog = scala.concurrent.future { models.Order.backlog(warehouse) } // Get a promise of the order backlog without blocking Async { backlog.map(value => Ok(value)) } } } |
This is important because it allows Play to release threads to a thread pool, making them available to process other HTTP requests, so the application can serve a large number of requests with a limited number of threads.
Modules—structuring your application
A Play module is a Play application dependency—either reusable third-party code or an independent part of your own application. The difference between a module and any other library dependency is that a module depends on Play and can do the same things an application can do.
Third-party modules
Modules make it possible to extend Play with functionality that you can use as if it were built-in, without bloating the core framework with features that not everyone needs.
Here are a few examples of third-party modules that provide different kinds of functionality:
- Deadbolt—Role-based authorization that allows you to restrict access to controllers and views
- Groovy templates—An alternative template engine that uses the Play 1.x Groovy template syntax
- PDF — Adds support for PDF output based on HTML templates
- Redis—Integrates Redis to provide a cache implementation
- Sass—Adds asset file compilation for Sass stylesheet files
For more information about these and other modules, see the Play Framework web site (http://www.playframework.org).
Extracting custom modules
One way to approach custom modules is to think of them as a way to split your applica- tions into separate reusable components, which helps keep individual applications and modules simple.
Module-first application architecture
Another approach is to always add new application functionality in a module, when you can, only adding to the main application when absolutely necessary.
With this approach, each application would consist of a smaller core of modelspecific functionality and logic, plus a constellation of modules that provide separate aspects of application functionality. Some of these modules would inevitably be shared between applications.
Deciding whether to write a custom module
Module architecture
A module is almost the same thing as a whole application.
It provides the same kind of things an application has: models, view templates,
controllers, static files, or other utility
code. The only thing a module lacks is its own configuration; only the main application’s
configuration is used. This means that any module configuration properties must be set
in the application’s conf/application.conf file.